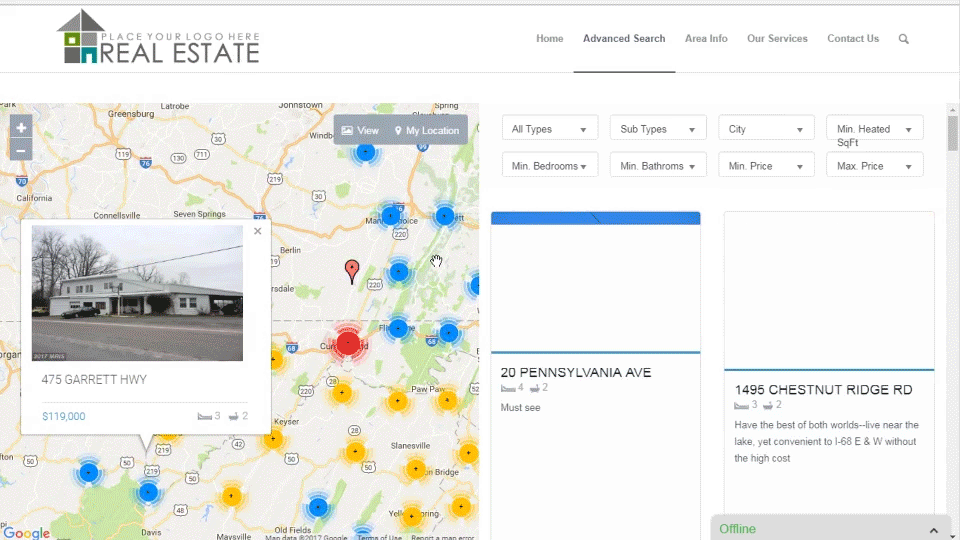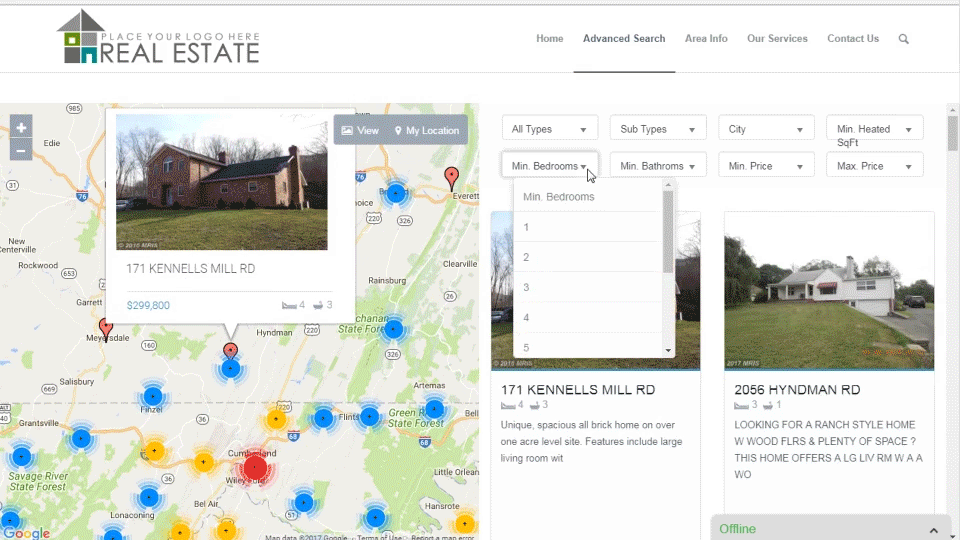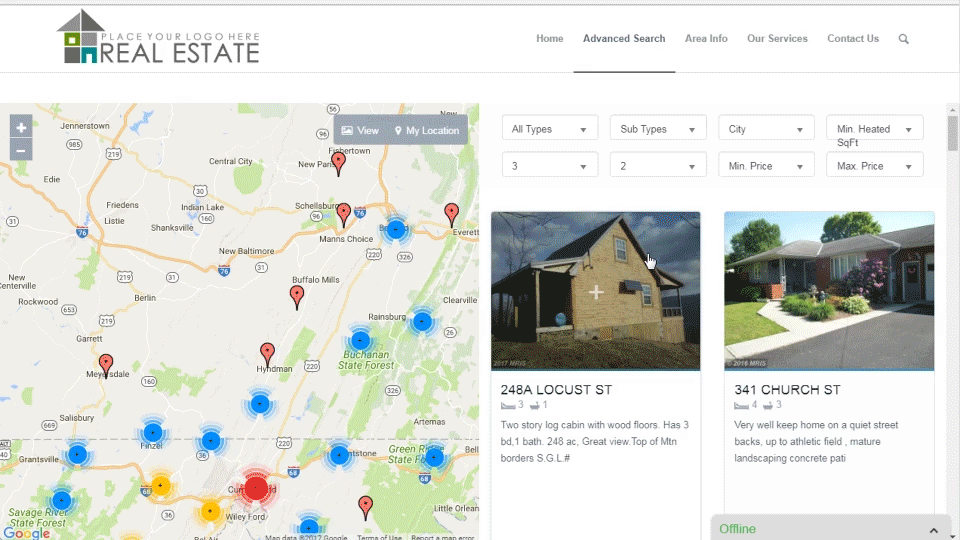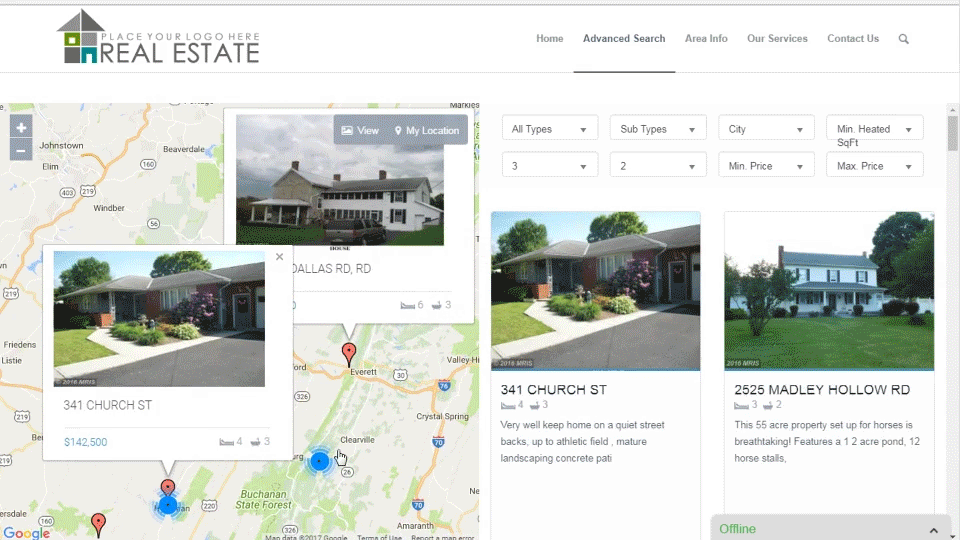
RETS PRO
WordPress Real Estate Plugin
Building RETS Websites Since 2002 – WordPress Plugin Since 2009
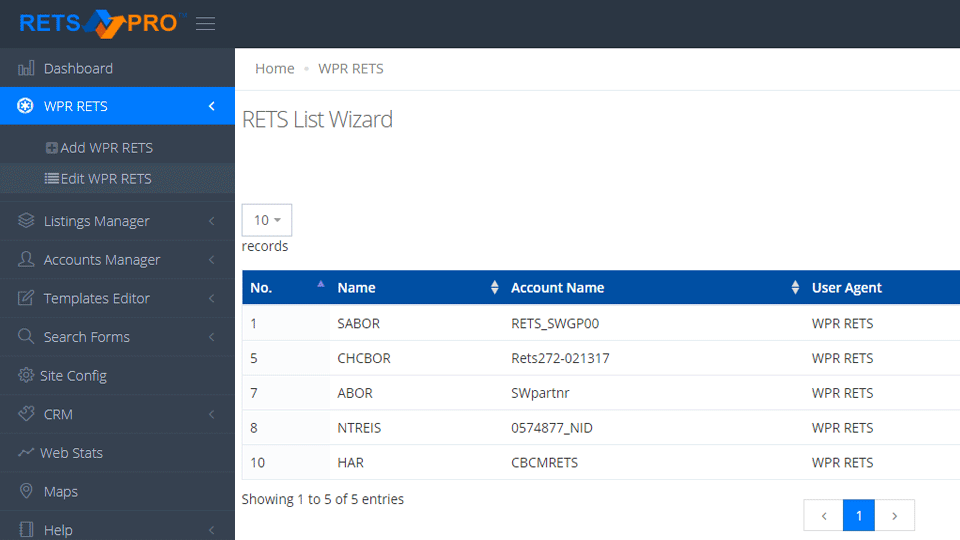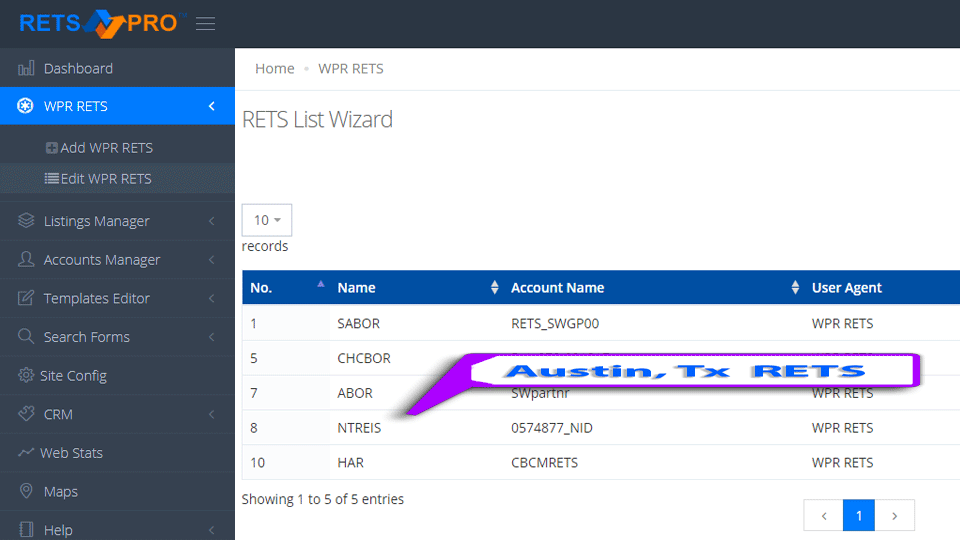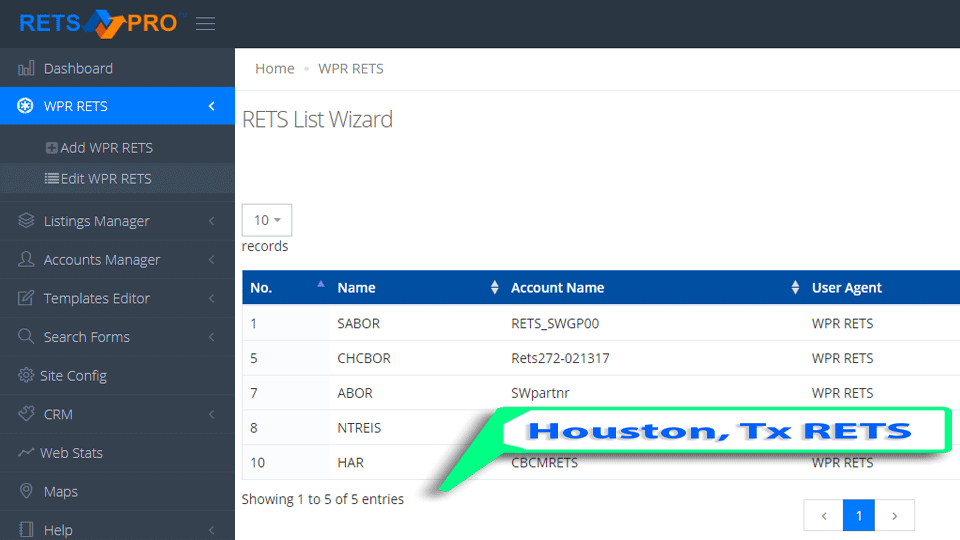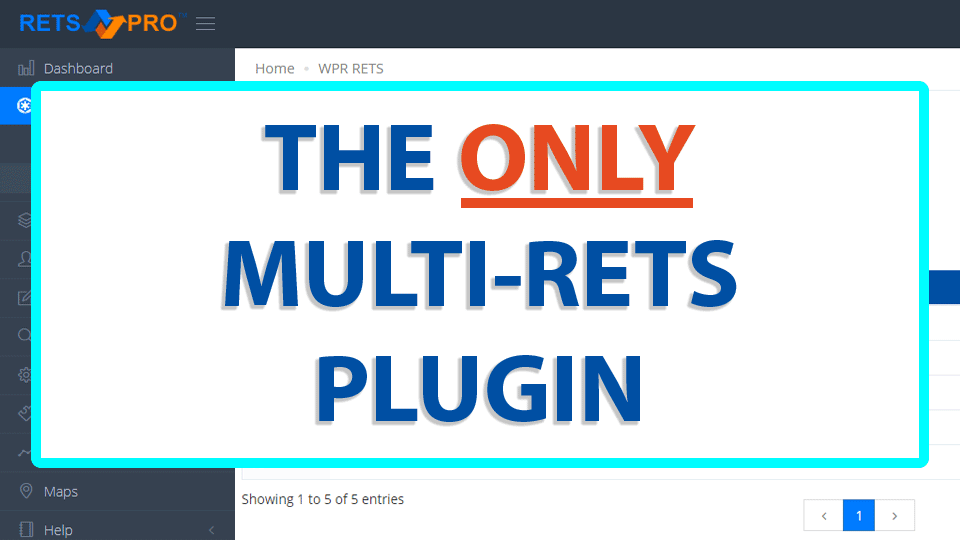
Built by SEO Professionals for their own clients, this is the only
100% Multi-RETS Compatible IDX WordPress Real Estate Plugin
that allows you to own the code and stop paying monthly fees.